Monitoring Cloudflare Logs with ClickStack
This guide shows you how to ingest Cloudflare logs into ClickStack using ClickPipes. Cloudflare Logpush writes logs to S3, and ClickPipes continuously ingests new files into ClickHouse. Unlike most ClickStack integration guides that use the OpenTelemetry Collector, this guide uses ClickPipes to pull data directly from S3.
A demo dataset is available if you want to explore the dashboards before configuring production ingestion.
Overview
Cloudflare Logpush exports HTTP request logs to destinations like Amazon S3. Forwarding these logs to ClickStack allows you to:
- Analyze edge traffic, cache performance, and security events alongside your other observability data
- Query logs using ClickHouse SQL
- Retain logs beyond Cloudflare's default retention
This guide uses ClickPipes to continuously ingest Cloudflare log files from S3 into ClickHouse.
Integration with existing Cloudflare Logpush
This section assumes you have Cloudflare Logpush configured to export logs to S3. If not, follow Cloudflare's AWS S3 setup guide first.
Prerequisites
- ClickHouse Cloud service running (ClickPipes is a Cloud-only feature — not available in ClickStack OSS)
- Cloudflare Logpush actively writing logs to an S3 bucket
- S3 bucket name and region where Cloudflare writes logs
Configure S3 authentication
ClickPipes needs permission to read from your S3 bucket. Follow the Accessing S3 data securely guide to configure either IAM role-based access or credentials-based access.
For full details on ClickPipes S3 authentication and permissions, see the S3 ClickPipes reference documentation.
Create ClickPipes job
- ClickHouse Cloud Console → Data Sources → Create ClickPipe
- Source: Amazon S3

Connection:
- S3 file path: Your Cloudflare logs bucket path with a wildcard to match files. If you enabled daily subfolders in Logpush, use
**to match across subdirectories:- No subfolders:
https://your-bucket.s3.us-east-1.amazonaws.com/logs/* - Daily subfolders:
https://your-bucket.s3.us-east-1.amazonaws.com/logs/**/*
- No subfolders:
- Authentication: Select your authentication method and provide the credentials or IAM Role ARN
Ingestion settings:
Click Incoming data, then configure:
- Toggle on Continuous ingestion
- Ordering: Lexicographical order

Cloudflare Logpush writes files with date-based naming (e.g., 20250127/...), which is naturally lexicographical. ClickPipes polls for new files every 30 seconds and ingests any file with a name greater than the last processed file.
Schema mapping:
Click Parse information. ClickPipes samples your log files and auto-detects the schema. Review the mapped columns and adjust types as needed. Define a Sorting key for the destination table — for Cloudflare logs, a good choice is (EdgeStartTimestamp, ClientCountry, EdgeResponseStatus).
Click Complete Setup.
When first created, ClickPipes performs an initial load of all existing files in the specified path before switching to continuous polling. If your bucket contains a large backlog of Cloudflare logs, this initial load may take some time.
Configure HyperDX data source
ClickPipes ingests Cloudflare logs into a flat table with Cloudflare's native field names. To view these logs in HyperDX, configure a custom data source that maps Cloudflare columns to HyperDX's log view.
- Open HyperDX → Team Settings → Sources
- Click Add source and configure the following settings. Click Configure Optional Fields to access all fields:
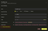
| Setting | Value |
|---|---|
| Name | Cloudflare Logs |
| Source Data Type | Log |
| Database | default |
| Table | cloudflare_http_logs |
| Timestamp Column | toDateTime(EdgeStartTimestamp / 1000000000) |
| Default Select | EdgeStartTimestamp, ClientRequestMethod, ClientRequestURI, EdgeResponseStatus, ClientCountry |
| Service Name Expression | 'cloudflare' |
| Log Level Expression | multiIf(EdgeResponseStatus >= 500, 'ERROR', EdgeResponseStatus >= 400, 'WARN', 'INFO') |
| Body Expression | concat(ClientRequestMethod, ' ', ClientRequestURI, ' ', toString(EdgeResponseStatus)) |
| Log Attributes Expression | map('http.method', ClientRequestMethod, 'http.status_code', toString(EdgeResponseStatus), 'http.url', ClientRequestURI, 'client.country', ClientCountry, 'client.ip', ClientIP, 'cache.status', CacheCacheStatus, 'bot.score', toString(BotScore), 'cloudflare.ray_id', RayID, 'cloudflare.colo', EdgeColoCode) |
| Resource Attributes Expression | map('cloudflare.zone', ClientRequestHost) |
| Implicit Column Expression | concat(ClientRequestMethod, ' ', ClientRequestURI) |
- Click Save Source
This maps Cloudflare's native columns directly to HyperDX's log viewer without any data transformation or duplication. The Body displays a request summary like GET /api/v1/users 200, and all Cloudflare fields are available as searchable attributes.
Verify data in HyperDX
Navigate to the Search view and select the Cloudflare Logs source. Set the time range to cover your data. You should see log entries with:
- Request summaries in the Body column (e.g.,
GET /api/v1/users 200) - Severity levels color-coded by HTTP status (INFO for 2xx, WARN for 4xx, ERROR for 5xx)
- Searchable attributes like
http.status_code,client.country,cache.status, andbot.score

Demo dataset
For users who want to test the integration before configuring their production Cloudflare Logpush, we provide a sample dataset with realistic HTTP request logs.
Start ClickPipes with the demo dataset
- ClickHouse Cloud Console → Data Sources → Create ClickPipe
- Source: Amazon S3
- Authentication: Public
- S3 file path:
https://datasets-documentation.s3.eu-west-3.amazonaws.com/clickstack-integrations/cloudflare/cloudflare-http-logs.json - Click Incoming data
- Select JSON as the format
- Click Parse information and review the detected schema
- Set the Table name to
cloudflare_http_logs - Click Complete Setup
The dataset includes 5,000 HTTP request log entries spanning 24 hours with realistic patterns including traffic from multiple countries, cache hits and misses, API and static asset requests, error responses, and security events.
Configure HyperDX data source
Follow the data source configuration steps to create a HyperDX source pointing to the cloudflare_http_logs table. If you already configured the source in the production integration section, this step is not needed.
Verify demo data
Navigate to the Search view in HyperDX, select the Cloudflare Logs source, and set the time range to 2026-02-23 00:00:00 - 2026-02-26 00:00:00.
You should see log entries with request summaries, searchable Cloudflare attributes, and severity levels based on HTTP status codes.
HyperDX displays timestamps in your browser's local timezone. The demo data spans 2026-02-24 00:00:00 - 2026-02-25 00:00:00 (UTC). The wide time range ensures you'll see the demo logs regardless of your location. Once you see the logs, you can narrow the range to a 24-hour period for clearer visualizations.
Dashboards and visualization
Import dashboard
- HyperDX → Dashboards → Import Dashboard

- Upload
cloudflare-logs-dashboard.json→ Finish Import

View dashboard

For the demo dataset, set the time range to 2026-02-24 00:00:00 - 2026-02-25 00:00:00 (UTC) (adjust based on your local timezone). The imported dashboard won't have a time range specified by default.
Troubleshooting
Data not appearing in ClickHouse
Verify the table was created and contains data:
If the table exists but is empty, check ClickPipes for errors: ClickHouse Cloud Console → Data Sources → Your ClickPipe → Logs. For authentication issues with private buckets, see the S3 ClickPipes access control documentation.
Logs not appearing in HyperDX
If data is in ClickHouse but not visible in HyperDX, check the data source configuration:
- Verify a source exists for
cloudflare_http_logsunder HyperDX → Team Settings → Sources - Ensure the Timestamp Column is set to
toDateTime(EdgeStartTimestamp / 1000000000)— Cloudflare timestamps are in nanoseconds and need to be converted - Verify your time range in HyperDX covers the data. For the demo dataset, use 2026-02-23 00:00:00 - 2026-02-26 00:00:00
Next steps
Now that you have Cloudflare logs flowing into ClickStack:
- Set up alerts for security events (WAF blocks, bot traffic spikes, error rate thresholds)
- Optimize retention policies based on your data volume
- Create additional dashboards for specific use cases (API performance, cache optimization, geographic traffic analysis)
Going to production
This guide demonstrates ingesting Cloudflare logs using a public demo dataset. For production deployments, configure Cloudflare Logpush to write to your own S3 bucket and set up ClickPipes with IAM role-based authentication for secure access. Select only the Logpush fields you need to reduce storage costs and ingestion volume. Enable daily subfolders in Logpush for better file organization and use **/* in your ClickPipes path pattern to match across subdirectories.
See the S3 ClickPipes documentation for advanced configuration options including SQS-based unordered ingestion for handling backfills and out-of-order files.
